
🐥
[Spark] cache()와 persist() 본문
스파크로 데이터를 처리하면 action 연산자 수행 시에 데이터가 로드된다.
반복된 동일한 연산을 한다면 매번 action 때 로드하지 않고 cache()와 persist()를 사용하여 데이터를 메모리에 상주시킬 수 있다.

캐시된 데이터는 storage memory에 보관된다.
1. cache() 와 persist()
cache와 persist 모두 동일한데 persist에서는 storageLevel을 설정해줄 수 있다는 점에서 차이가 있다.
`cache()`는 Dataframe 의 경우`persist(storageLevel=MEMORY_AND_DISK)` , RDD의 경우 ` persist(storageLevel=MEMORY_ONLY)` 와 같은 함수이다.
https://spark.apache.org/docs/latest/sql-ref-syntax-aux-cache-cache-table.html
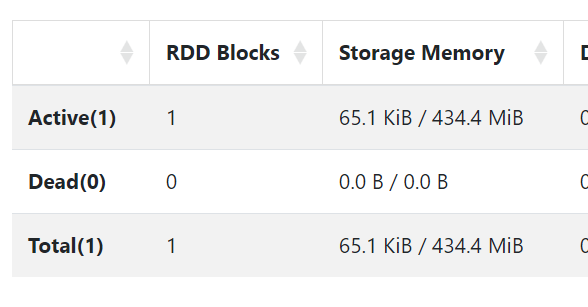
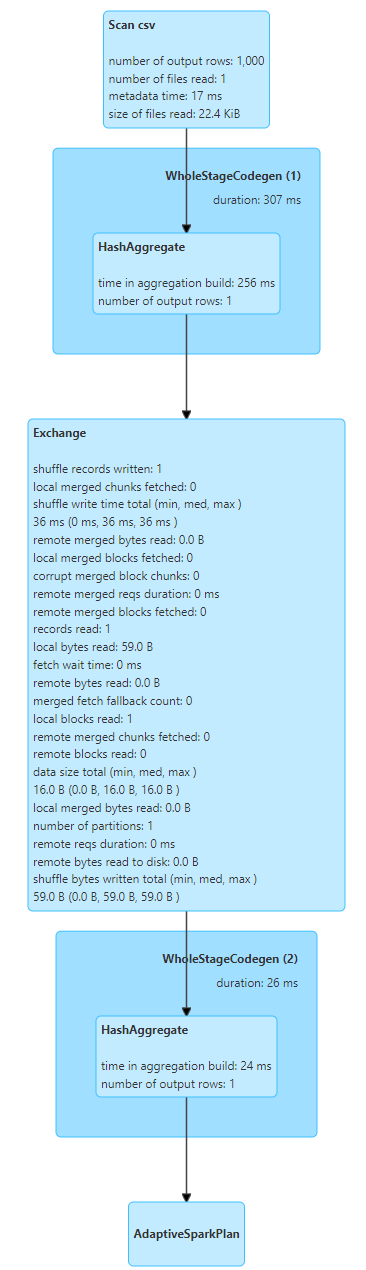
`df.cache()`를 실행했을 때와 실행하지 않았을 때의 쿼리 수행 단계와 메모리 사용량을 비교해보았다.
csv_file_path = my_path
df = spark.read.schema(table_schema).csv(csv_file_path)
df.cache()
df.count()
| cache 미수행 시 | cache 수행 시 |
 |
 |
 |
 |
storage memory에서 cache 미수행시보다 수행시에 사용량이 증가한 것을 확인할 수 있었다.
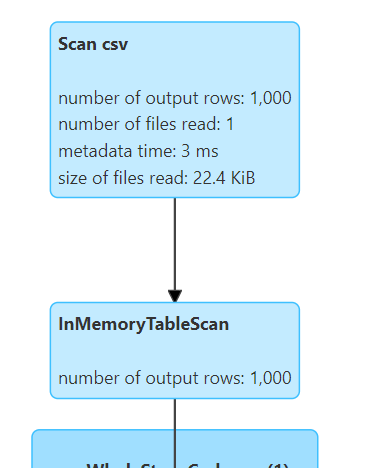
`cache()` 를 실행했을 때 중간에 `InMemoryTableScan`이라는 단계가 추가된 것을 볼 수 있다.
캐시된 상태에서 다른 연산을 수행했을 때에는 아래와 같이 csv 파일에서 다시 로드하지 않고 `InMemoryTableScan`을 통해 1000개의 rows를 불러오는 것을 확인할 수 있었다.
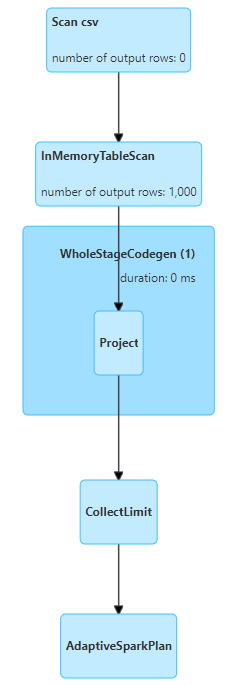
메모리에서 해제하고 싶을 때에는 `unpersist()`를 사용해주면 된다.
df.unpersist()
2. StorageLevel
storageLevel 을 살펴보면 아래와 같다.
| Level |
Space Used |
CPU Time |
In memory |
On disk |
Nodes with data |
| MEMORY_ONLY |
High |
Low |
Y |
N |
1 |
| MEMORY_ONLY_2 |
High |
Low |
Y |
N |
2 |
| MEMORY_ONLY_SER |
Low |
High |
Y |
N |
1 |
| MEMORY_ONLY_SER_2 |
Low |
High |
Y |
N |
2 |
| MEMORY_AND_DISK |
High |
Medium |
Some |
Some |
1 |
| MEMORY_AND_DISK_2 |
High |
Medium |
Some |
Some |
2 |
| MEMORY_AND_DISK_SER |
Low |
High |
Some |
Some |
1 |
| MEMORY_AND_DISK_SER_2 |
Low |
High |
Some |
Some |
2 |
| DISK_ONLY |
Low |
High |
N |
Y |
1 |
| DISK_ONLY_2 |
Low |
High |
N |
Y |
2 |
Serialization
RDD 캐싱시 직렬화된 java 객체로 저장한다. 직렬화를 통해 storage cost를 줄일 수 있으나, deserialize를 해야하기 때문에 CPU Time이 더 높다.
spark에서는 java serializer를 기본 serializer로 사용하고 있다. java와 scala에서는 kryo serializer를 사용할 수 있는데 java serializer보다 storage cost 가 더 좋다고 한다.
serialization 하는 캐싱과 하지 않는 캐싱 시에 메모리 사용량을 확인해봤다.
1. MEMORY_ONLY
df = spark.read.schema(table_schema).csv(csv_file_path)
# MEMORY_ONLY
df.persist(StorageLevel(False, True, False, True, 1))
df.show()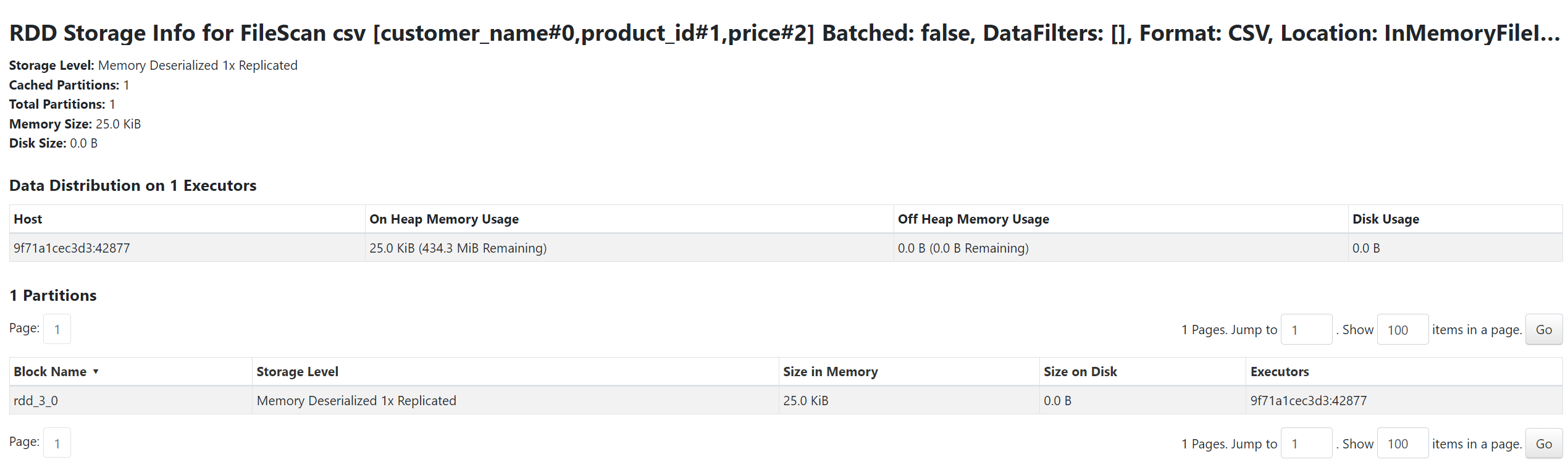
2. MEMORY_ONLY_SER
df = spark.read.schema(table_schema).csv(csv_file_path)
# MEMORY_ONLY_SER
df.persist(StorageLevel(False, True, False, False, 1))
df.show()
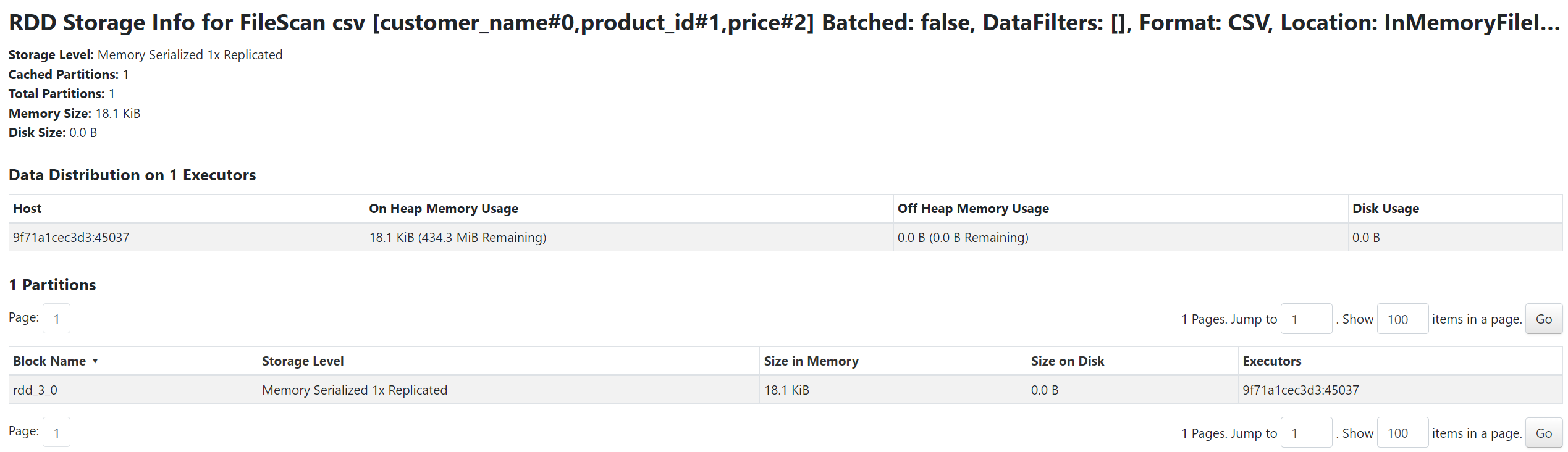
serialization 되었을 때가 안되었을 때보다 더 작은 사이즈가 메모리에 로드된 것을 확인할 수 있었다.
(storagelevel 참고: https://github.com/apache/spark/blob/master/core/src/main/java/org/apache/spark/api/java/StorageLevels.java#L25)
3.언제?
여러번 재사용을 할 것으로 예상될 때 사용한다.
transformation을 충분히 마친 후 action 직전에 캐싱해주면 좋다.
예를들어 아래와 같이 action 연산이 2회 있는 경우,
df = spark.read.schema(table_schema).csv(csv_file_path)
# Action 1
df.show()
# Action 2
B = df.count()
print(B)아래와 같이 두 개의 쿼리가 만들어지고, 두 개의 쿼리에서 각각 scan을 하는 것을 알 수 있다.
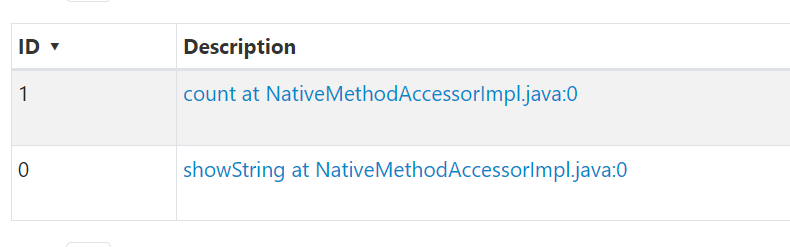
 |
 |
아래와 같이 action 전에 cache를 넣어주면,
df = spark.read.schema(table_schema).csv(csv_file_path)
df.cache()
# Action 1
df.show()
# Action 2
B = df.count()
print(B)
마찬가지로 두 개의 쿼리가 만들어지지만 첫번째 action에서만 scan이 일어나고 이후 count() 에서는 InMemoryTableScan을 통해 데이터를 로드한 것을 알 수 있다.
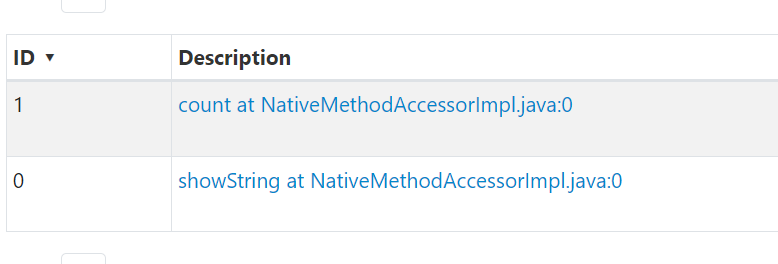
 |
 |
예시에서는 데이터 사이즈도 작고 downstream 작업이나 복잡한 로직이 없어 수행시간은 동일했는데, transformation이 많거나 더 큰 데이터를 다룰 때에는 캐시를 적절하게 사용하면 성능향상을 볼 수 있을 것 같다.
'데이터 > Spark' 카테고리의 다른 글
| [Spark] SQL Hint (0) | 2024.04.01 |
|---|---|
| [Spark] 스파크 스케쥴링 (0) | 2024.04.01 |
| [Spark] Speculative Execution (0) | 2024.04.01 |
| [Spark] Logical Plan 과 Physical Plan (0) | 2024.03.25 |
| [Spark] RDD vs Dataframe (2) | 2024.03.24 |

