
🐥
[Spark] Structured Streaming - stateful transformation과 Window operation 본문
[Spark] Structured Streaming - stateful transformation과 Window operation
•8• 2024. 4. 16. 22:24streaming 코드를 작성하면서 filter, count 등 여러가지 연산자를 사용할 수 있다.
과거 데이터의 정보가 필요없는 stateless 연산자와, 과거의 데이터가 필요해 데이터 유지가 필요한 statefull 연산자로 나눌 수 있다.
- Stateless Trasformation
과거의 데이터와 상관 없이 현재의 데이터만 사용하는 연산자 - Stateful Transfmraion
이전 배치의 데이터의 유지가 필요한 연산자
예: aggreagion, counter, join, group, windowing 등
Stateless Transformation
각 배치를 이전 배치를 참조하지 않고 독립적으로 처리한다. -> 배치의 출력이 해당 배치의 데이터만을 기반으로 함을 의미
select, filter, map, flatmap, explode 와 같은 연산자가 있다.
이전 배치에 대한 메모리가 필요하지 않아 stateful보다 비교적 빠르고 메모리를 덜 소모한다.
여러 노드에서 state를 추적할 필요가 없기 때문에 수평으로 확장하기가 쉽다.
<Usecase>
- 각 데이터를 독립적으로 처리할 수 있는 작업일 때
- 현재 결과를 결정하기 위해 과거 데이터를 참조할 필요가 없을 때
Stateful Transformation
여러 배치에서 상태를 유지한다. -> 배치의 출력이 해당 배치의 데이터 뿐만 아니라 이전 배치에서 누적된 state에 따라 달라짐을 의미
aggregation, count, join, grouping, window 등의 연산자가 있다.
일반적으로 stateless 작업보다 더 느리고 더 많으 메모리를 사용한다.
<Usecase>
- 집계 결과가 필요할 때
- window 계산이 필요할 때
- continuous stream에서 사용자 세션과 같은 상태 저장 정보를 사용할 때
Window Operations
spark streaming에서는 데이터를 윈도우 단위로 sliding 해가며 transfomation할 수 있는 "windowed computations"를 제공한다.
지원되는 윈도우 종류는 아래와 같다
- spark 3.2 이전: tumbling window, sliding window
- spark 3.2 부터: tumbling window, sliding window, session window(updated!)
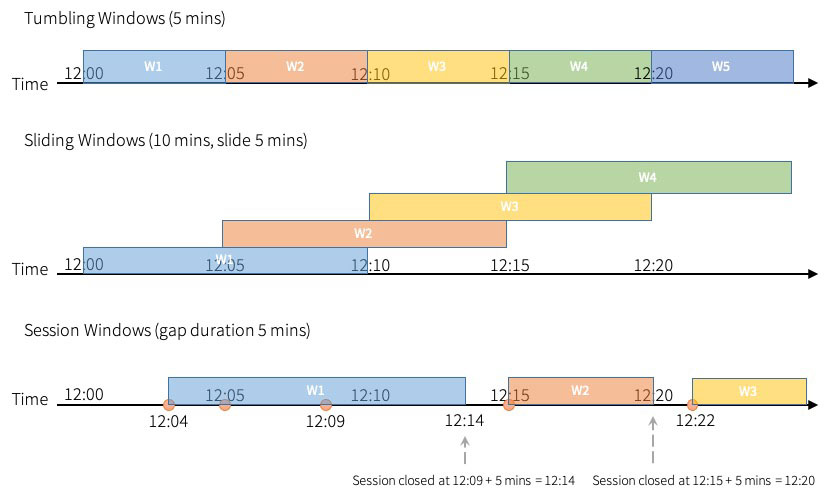
위 이미지에서 각 윈도우간의 특징을 잘 설명해주고 있다.
- Tumbling Windows는 fixed size, 겹치지 않는 연속된 time interval이다. input은 한가지 window에서만 바인딩 될 수 있다.
- Sliding Window는 tumbling window와 마찬가지로 "fixed size" 를 가지지만 slide의 지속 시간이 window 지속 시간보다 작으면 window가 겹칠 수 있고, 이 경우 하나의 input이 여러개의 window에 바인딩될 수 있다.
- Session Window는 window size에 대해 동적인 크기를 갖는다. 시간 단위가 아니고, input으로 시작하며, 간격 내에 다음 입력이 수신되만 확장될 수 있다. 만약 간격 내에 수신된 input이 없다면 session window는 닫힌다.
관련해서 여기에 추가로 비슷한 내용 정리해놓았다.
사용 방법은 아래와 같다.
# tumbling window
windowedCountsDF = \
eventsDF \
.withWatermark("eventTime", "10 minutes") \
.groupBy(“deviceId”, window("eventTime", "10 minutes") \
.count()
# sliding window
windowedCountsDF = \
eventsDF \
.withWatermark("eventTime", "10 minutes") \
.groupBy(“deviceId”, window("eventTime", "10 minutes", "5 minutes")) \
.count()
# session window
windowedCountsDF = \
eventsDF \
.withWatermark("eventTime", "10 minutes") \
.groupBy("deviceId", session_window("eventTime", "5 minutes")) \
.count()window
` pyspark.sql.functions.window(timeColumn, windowDuration, slideDuration=None, startTime=None)`
- timeColumn: window를 계산할 기준 열을 지정한다. pyspark.sql.types.TimestampType.포맷이어야 함.
- windowDuration: window size를 결정한다.
- slideDuration: 슬라이드 interval 값을 결정한다. 값이 있다면 sliding window, 없다면 tumbling window로 실행된다.
- startTime: 창 간격을 시작할 1970-01-01 00:00:00 UTC에 대한 offset이다. interval 시작 시점을 결정한다.
예를들어 아래와 같은 window function이 있다고 가정해보면
window("timestamp", "5 minutes", "1 minute")윈도우는 아래와 같이 생성된다.
09:00:00-09:05:00
09:01:00-09:06:00
09:02:00-09:07:00 ...만약 startTime을 30초로 지정하면
window("timestamp", "5 minutes", "1 minute", "30 seconds")윈도우는 아래와 같이 생성될 것이다.
09:00:30-09:05:30
09:01:30-09:06:30
09:02:30-09:07:30 ...session_window
`pyspark.sql.functions.session_window(timeColumn: ColumnOrName, gapDuration: Union[pyspark.sql.column.Column, str])`
- timeColumn: window를 계산할 기준 열 이름 또는 열. TimestampType이나 TimestampNTZType이어야 한다.
- gapDuration: 세션 시간 초과를 지정하는 python 문자열/열. 정적 값이거나 동적으로 지정하는 표현식일 수 있다.
dynamic session time을 설정할 때에는 gapDuration을 표현식으로 사용할 수 있다.
# Define the session window having dynamic gap duration based on eventType
session_window expr = session_window(events.timestamp, \
when(events.eventType == "type1", "5 seconds") \
.when(events.eventType == "type2", "20 seconds") \
.otherwise("5 minutes"))
# Group the data by session window and userId, and compute the count of each group
windowedCountsDF = events \
.withWatermark("timestamp", "10 minutes") \
.groupBy(events.userID, session_window_expr) \
.count()
session_window에는 아래와 같이 session을 merge하는 과정이 있다.
event 간격 기간이 겹치는 경우 (파랑-주황-노랑 / 초록 ), 세션을 하나로 묶는다 (빨강 / 보라)
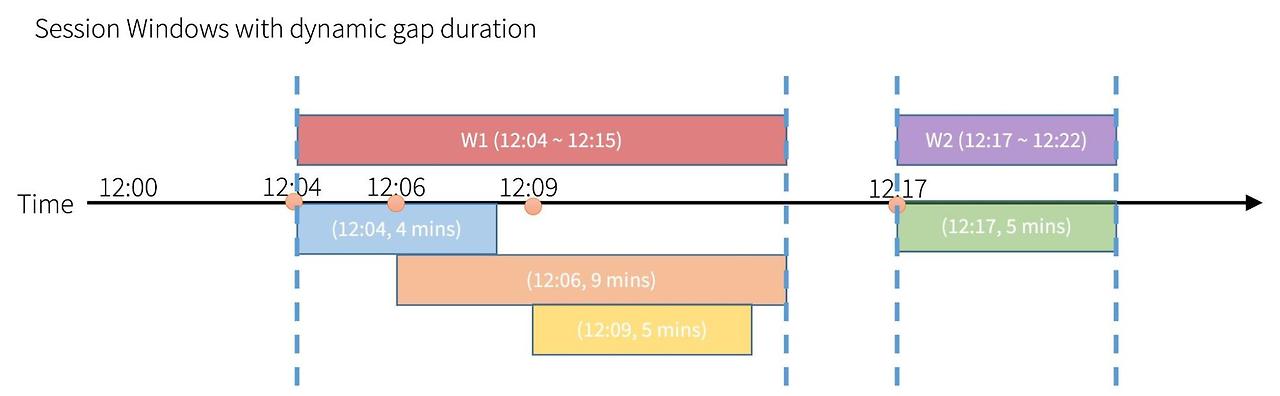
session window는 유휴 시간 (session interval)로 구분된 활성 이벤트 기간을 그룹화하여 세션 간격 내에서 발생하는 모든 이벤트를 기존 세션에 merge 한다.* state store: 읽기/쓰기를 제공하는 versioned key-value store. batch 간 stateful operation을 처리하기 위해 state store provider를 사용할 수 있다. (참고)
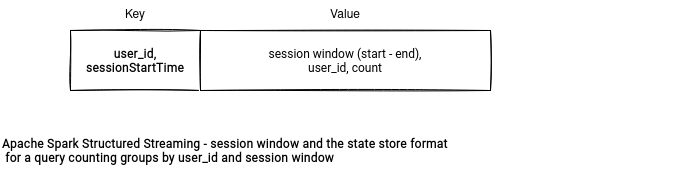
session window는 update output mode를 지원하지 않는다.
참고
https://github.com/apache/spark/pull/12008
https://dataninjago.com/2022/07/24/spark-structured-streaming-deep-dive-8-session-window/
'데이터 > Spark' 카테고리의 다른 글
| [Spark] 스파크 스트리밍의 이벤트 시간 처리와 Watermark (0) | 2024.04.21 |
|---|---|
| [Spark] Spark Structured Streaming - Fault Tolerance (0) | 2024.04.04 |
| [Spark] Spark Structured Streaming 개요 (0) | 2024.04.04 |
| [Spark] Accumulator와 Broadcast (공유변수) (0) | 2024.04.01 |
| [Spark] SQL Hint (0) | 2024.04.01 |



