
🐥
Spark, Trino on kubernetes 본문
Spark on Kubernetes
Spark에서는 cluster manager로 kubernetes를 지원한다(2.3 버전부터). kubernetes가 관리하는 클러스터에서 spark가 실행되고, 네이티브 kubernetes 스케줄러를 사용한다.
- 장점
- 컨테이너 기반 워크로드
- 쿠버네티스의 HPA를 사용해 executor 수를 자덩으로 조정할 수 있다.
- 작업 및 배포 관리 유현성
- 단점
- 초기 설정 복잡성
- kubernetes 스케줄링 문제: third party scheduler를 사용해야 함
- kubernetes 클러스터의 상태에 spark 성능 및 가용성에 영향을 받음
- 복잡한 모니터링 및 로깅 - spark 자체 로그, pod 로그, 시스템 로그, 이벤트 로그 등...
- data locality - kubernetes에서는 spark executor가 반드시 데이터가 위치한 노드에 배치되지 않을 수 있어 데이터 이동 비용이 커질 가능성이 있음.
kubernetes cluster에서 spark job을 제출할 때에는 spark-submit / SparkOperator 두 가지 방식을 이용할 수 있다.
spark-submit
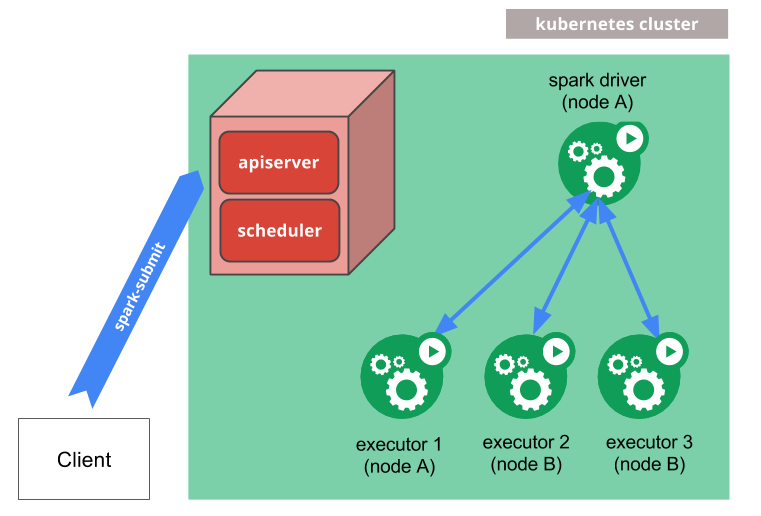
kubernetes 클러스터에 스파크 어플리케이션을 submit 하는 메커니즘은 아래와 같다.
- spark는 kubernetes pod 에서 실행되는 spark driver를 생성한다.
- driver는 pod 에서 실행되는 executor를 생성하고, 어플리케이션 코드를 실행한다.
- 어플리케이션이 완료되면 executor pod 은 종료되고 정리된다.
driver pod는 로그를 유지하고 kubernetes api에서 completed 상태를 유지하고, gc되거나 수동으로 정리될때까지 유지된다.
spark-submit 시 각 과정을 살펴보면 아래와 같다.
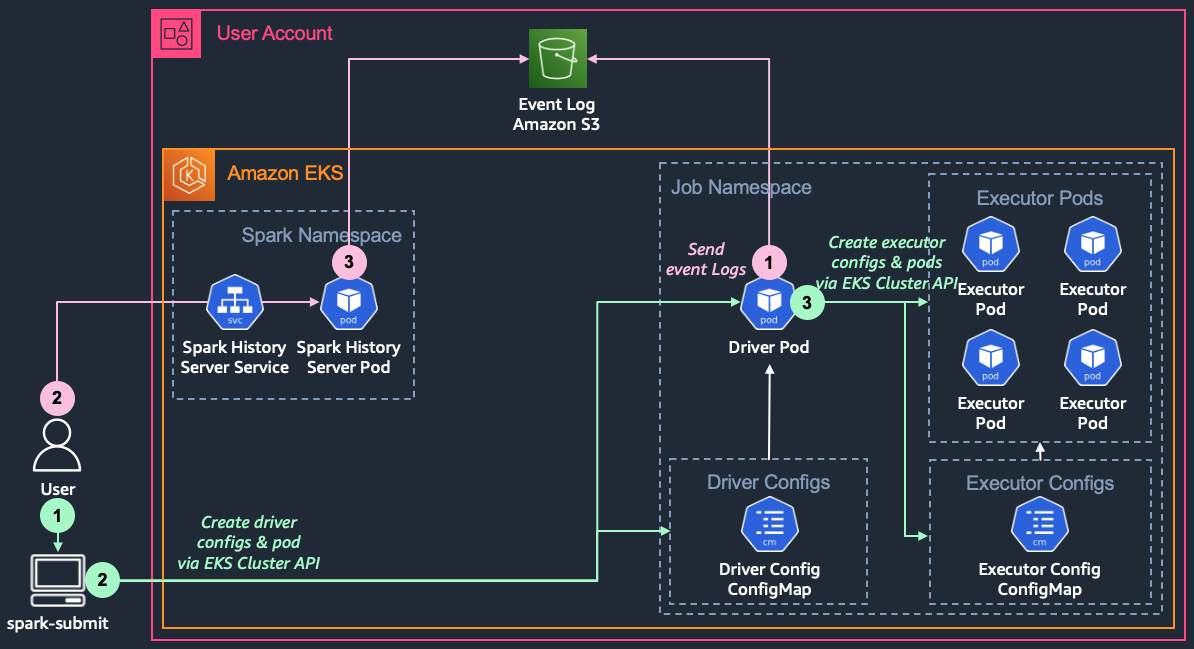
- spark-submit cli 제출
- cli를 통해 submit이 제출되면 driver pod과 spark job 구동에 필요한 설정 정보를 driver configmap으로 생성한다.
- diver configmap을 driver pod의 볼륨으로 설정하여 driver pod을 생성한다.
- driver pod에서는 driver configmap의 설정정보를 참조한다.
- executor에게 driver pod의 ip 정보를 제공하기 위해 제공하기 위한 driver service도 별도 생성하고, executor에게 설정을 전달하기 위한 executor configmap을 생성한다.
- driver는 driver configmap을 참고하여 executor configmap을 volume으로 사용하는 executor pod을 생성한다.
- executor pod 내부의 executor는 driver의 headless service를 통해 driver pod의 ip 정보를 얻어내고, driver pod에 접속한다.
spark operator
spark operator는 spark job 제출을 kubernetes object로 정의하도록 도와준다. 사용자는 SparkApplication, ScheduledSparkApplication object를 정의하여 job을 제출한다.
- SparkApplication: Ad-hoc 형태로 하나의 Spark Job을 제출하는 경우 사용
- ScheduledSparkApplication: 주기적으로 Spakr Job을 제출해야 하는 경우에 이용
사용자는 sparkctl을 사용하거나 직접 SparkApplication을 만들고, SparkOperator는 SparkApplication을 감지하고 내부에 존재하는 spark-submit cli를 이용하여 spark job을 제출한다.
sparkctl은 아래 README에 잘 설명되어 있다.
https://github.com/kubeflow/spark-operator/blob/master/sparkctl/README.md

SparkApplication 의 생성 예는 아래와 같다.
spec.timeToLiveSeconds를 설정하여 completed된 pod이 일정 시간 이후 삭제될 수 있도록 설정할 수 있다.
apiVersion: sparkoperator.k8s.io/v1beta2
kind: SparkApplication
metadata:
name: spark-pi
namespace: default
spec:
timeToLiveSeconds: 60
type: Scala
mode: cluster
image: spark:3.5.1
mainClass: org.apache.spark.examples.SparkPi
mainApplicationFile: local:///opt/spark/examples/jars/spark-examples_2.12-3.5.1.jar
스케줄러
spark on kubernetes에서는 driver 가 executor를 관리하므로 동적으로 리소스를 확장할 수 있지만, driver가 생성되기 전까지 쿠버네티스 스케줄러는 전체 executor에 필요한 리소스를 알 수 없다.
기본 스케줄러 문제점은 여기 자세히 설명되어 있다.
쿠버네티스의 기본 스케줄러는 배치 작업에 최적화된 형태가 아니기 때문에 다른 커스텀 배치 스케줄러 사용이 필요하다.
spark 3.4 부터는 volcano와 apache yunikorn customized 스케줄러를 공식적으로 지원한다.
Trino on Kubernetes
Kubernetes에서 Trino를 배포하면 아래와 같은 작업을 실행할 수 있다.
- 간단한 scale up/down
- worker 가 죽어도 다시 시작할 수 있음
- HPA와 사용자 정의 metric을 통한 오토 스케일링


참고
Spark
https://spark.apache.org/docs/latest/running-on-kubernetes.html#how-it-works
https://ssup2.github.io/blog-software/docs/theory-analysis/spark-on-kubernetes/
https://interp.blog/k8s-headless-service-why/
https://aws.amazon.com/ko/blogs/tech/amazon-eks-spark-job-comparison/
https://swalloow.github.io/spark-on-kubernetes-scheduler/
https://spot.io/blog/apache-spark-performance-benchmarks-show-kubernetes-has-caught-up-with-yarn/
Trino
https://spot.io/blog/apache-spark-performance-benchmarks-show-kubernetes-has-caught-up-with-yarn/
https://trino.io/episodes/24.html
https://github.com/joshuarobinson/trino-on-k8s